最近在利用Python获取网络数据的过程中出现一个问题,系统会时不时抛出UnicodeEncodeError的错误,并停止运行,严重影响了其它功能的运行。程序类似下面这样:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib2
print urllib2.urlopen("http://www.example.com/examplepath").read()
报错信息如下: UnicodeEncodeError: ‘gbk’ codec can’t encode character u’\u2022′ in position XXXX: illegal multibyte sequence
经过检查,发现是因为获取的远程文件中含有”·”这个字符,官方解释是“着重号(BULLET)”,其unicode编码是u+2022,其它关于这个符号的介绍,可以点击这里。也就是说,因为获取到的远程内容中含有着重号这个字符,所以导致程序出现UnicodeEncodeError。
在Python的wiki页面,找到了一篇关于PrintFails的说明:
如果你用print函数向控制台输出一个unicode的字符串,将会得到下面的提示
>>> print u"\u03A9"
Traceback (most recent call last):
File "<stdin>", line 1, in ?
File "C:\Python24\lib\encodings\cp866.py", line 18, in encode
return codecs.charmap_encode(input,errors,encoding_map)
UnicodeEncodeError: 'charmap' codec can't encode character u'\u1234' in position
0: character maps to <undefined>
This means that the python console app can’t write the given character to the console’s encoding.
More specifically, the python console app created a _io.TextIOWrapperd instance with an encoding that cannot represent the given character.
sys.stdout –> _io.TextIOWrapperd –> (your console)
To understand it more clearly, look at:
sys.stdout
sys.stdout.encoding — /!\ This seems to work on one of my computers (Vista,) but not on another of my computers (XP.) I haven’t looked into differences of situation in detail.
要理解这段说明,我们先要分析一下下面的问题:
文件编码与变量编码
Python内部是如何处理各种不同的编码的呢?当远程文件的编码和本地的编码不一样时,Python会进行怎样的处理?
我们知道,现在世界上存在各种各样的字符编码,光中国都有gb2312,gbk等编码,还有我们最为熟悉的ASCII,几乎世界上各个国家和地区都有自己的编码,这些编码有一个特点,几乎都兼容ASCII码,这也就意味着不管你用什么样的编码,python程序文件中内容都是一样的(除开字符串),那么python如何对不同编码文件的字符串进行处理呢?例如如下一段代码:
#!/usr/bin/env python
# -*- coding:gbk -*-
stra = "你"
strb = u"你"
print stra
print strb
print stra.encode("hex")
print hex(ord(strb))
print strb.encode("utf-8").encode("hex")
print isinstance(stra,str)
print isinstance(strb,unicode)
首先,这个python文件以gbk的方式保存,并在头部声明了编码方式为gbk,第三行和第四行分别声明了两个变量code,不同的是strb是以unicode的方式,而实际上这个文件保存在硬盘上的编码都一样,而是在程序加载之后,解释器更改了变量内部的编码。第6行和第7行分别打印出变量stra和strb在内存中的表示方式,可以看到gbk编码的”0xc4e3″确实代表的是“你”,而unicode的”0x4f60″代表的也是“你”,实际上python2中,python的字符串对象分为两类:string和unicode string.
把上面的程序文件编码方式改成utf-8或者其它编码,发现只有stra的编码发生了变化,其它的运行结果和原来的一样。这里可以得出结论:
1,程序中的string对象的编码方式和程序文件的编码方式是一样的
2,unicode string对象的编码方式不受程序文件的影响
3,继续验证可以得出,对于使用控制台运行的程序,string对象的编码则和控制台的编码方式有关,例如中文windows控制台代码页为cp936(gbk),则string对象的编码也为gbk
编码转换
Python提供encode和decode两个函数对编码进行转换,encode以指定的编码格式编码字符串,decode则以指定的格式解码字符串。
需要注意的是,encode是以字符串对象的编码格式为基础,转化成指定的编码;decode则是以指定的编码格式解码字符串为unicode编码,如:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
stra = "Hello"
print stra.encode("gbk").encode("hex") #打印以gbk编码的Hello的16进制数
print stra.decode("utf-8").encode("hex") #打印以unicode编码的Hello的二进制
有了encode和decode,就可以自由的对字符串进行编码和解码了。
而在Python内部,这样实现对字符编码的转换:
1, 读取文件
2, 根据文件的编码,把转换成unicode
3, 转换成utf-8的编码
4, 读取utf-8的文件内容
5, 编译,从给定的unicode数据创建unicode对象,根据源文件的编码格式,重新把转换成utf-8的数据重新编码成8-bit string data,并创建字符串对象
Python代码转换原理
Unicode字符编码的代码点(code point)是从0到0x10ffff,在内存中,这些字节必须被转换成单个字节进行存储,如果转换成ASCII码,遵循以下原则:
1, 如果当前代码点小于128,则保持原有代码点不变即可
2, 如果代码点大于等于128,这个unicode编码则不能被转化成这个编码(Python将会产生一个UnicodeEncodeError异常)
而对于Unicode转UTF-8编码,遵循以下原则:
1, 如果代码点小于128,将会转变成相应的字节值
2, 如果代码点在128到0x7ff之间,将会转换成128到255之间的双字节序列
3, 如果代码点待遇0x7ff,将会转换成128到255之间的双字节或三字节序列
UTF-8的好处有很多,一是节省空间完全兼容ASCII,二是Unicode所有码点都可以映射到UTF-8上,不会导致出现UnicodeError的错误
而对于中文来说,Unicode转GBK(微软叫cp936)有更加复杂的实现,GBK和Unicode的映射表可以点击这里。
Python字符输出流程
上面讲到了Python的字符型变量的编码和转换方式,我们了解到当编码在转换过程中遇到此编码体系中没有的码点时,就会抛出UnicodeEncodeError的错误。那么Python是如何输出一个字符的呢,同样的编码东西为什么有时候输出没有错误,有时候会有错误?例如上面说道的U+2022这个unicode表示的着重符,windows下print u”\u2022″会出现错误,而Linux下则输出正常。
Python IO
Python提供了三种类型的IO层,raw IO层,buffered IO层和Text IO层,它们分别由不同的抽象基类定义。raw IO和buffered IO层用来处理字节,textIO用来处理字符。其结构如下:
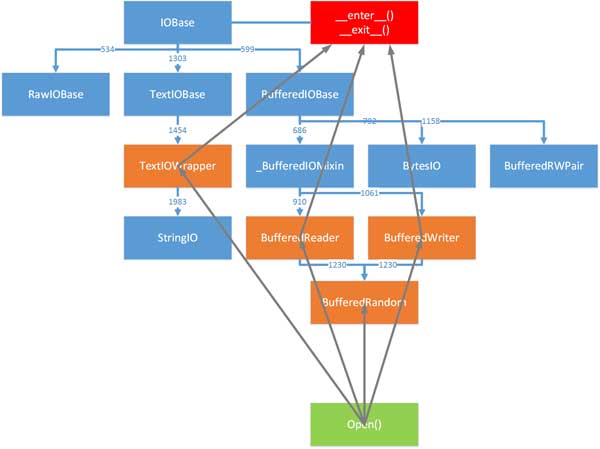
上文中讲到,print的输出,是通过sys.stdout到TextIOWrapper来实现的,而对于TextIOWrapper来说,它提供从数据流中读写字符串的功能,还提供了通用换行符和字符的编码和解码,它是对字符进行操作,而不是字节。TextIOWrapper接收5个参数,返回一个可以读写的对象,相关介绍可以点击这里。它的参数中有一项encoding,用来指定它读取的数据流的编码或解码方式,默认值是locale.getpreferredencoding()(终端编码)。
Unicode Output
所有的Unicode对象都有一个encode的方法,当Unicode对象需要输出时,系统会根据给定的编码自动把Unicode对象转化成普通字符。这也就以为着,在Python中:
print u := print u.encode() # using the
str(u) := u.encode() # using the
repr(u) := “u%s” % repr(u.encode(‘unicode-escape’))
所以,根据以上理论,一个Unicode字符的定义和输出实际上经过了很多轮的处理。而在输出过程中,首先调用TextIOWrapper,对字符进行encode,返回一个文件对象,然后进行写操作,这时候如果目标编码和源编码没有对应的值,例如unicode转化成ASCII或gbk则就有会出现UnicodeEncodeError的错误,当然如果目标编码是UTF-8,由于unicode的所有码点utf-8都可以表示,则不会出现任何错误。而对于中文版的windows来说,其控制台编码通常为cp936(gbk),对于一些不在其码点上的字符,python就会抛出错误。